

|
Theme-based PageRank For many years now, the topic- or theme-based homogeneity of websites has been dicussed as a possible ranking criterion of search engines. There are various theoretical approaches for the implementation of themes in search engine algorithms which all have in common that web pages are no longer ranked only based on their own content, but also based on the content of other web pages. For example, the content of all pages of one website may take influence on the ranking of one single page of this website. On the other hand, it is also conceivable that one page's ranking is based on the content of those pages which link to it or which it links to itself. The potential implementation of a theme-based ranking in the Google search engine is discussed controversially. In search engine optimization forums and on websites on this topic we can over and over again find advice that inbound links from sites with a similar theme to our own have a larger influence on PageRank than links from unrelated sites. This hypothesis shall be discussed here. Therefore, we first of all take a look at two relatively new approaches for the integration of themes in the PageRank technique: on the one hand the "intelligent surfer" by Matthew Richardson and Pedro Domingos and on the other hand the Topic-Sensitive PageRank by Taher Haveliwala. Subsequently, we take a look at the possibility of using content analyses in order to compare the text of web pages, which can be a basis for weighting links within the PageRank technique. The "Intelligent Surfer" by Richardson and Domingos Matthew Richardson and Pedro Domingos resort to the Random Surfer Model in order to explain their approach for the implementation of themes in the PageRank technique. Instead of a surfer who follws links completely at random, they suggest a more intelligent surfer who, on the one hand, only follows links which are related to an original search query and, on the other hand, also after "getting bored" only jumps to a page which relates to the original query. So, to Richardson and Domingos' "intelligent surfer" only pages are relevant that contain the search term of an initial query. But since the Random Surfer Model does nothing but illustrate the PageRank technique, the question is how an "intelligent" behaviour of the Random Surfer influences PageRank. The answer is that for every term occuring on the web a separate PageRank calculation has to be conducted and each calculation is solely based on links between pages which contain that term. Computing PageRank this way causes some problems. They especially appear for search terms that do not occur so often on the web. To make it into the PageRank calculations for a specific search term, that term has not only to appear on someone's page, but also on the pages that link to it. So, the search results would often be based on small subsets of the web and may omit relevant sites. In addition, using such small subsets of the web, the algorithms are more vulnerable to spam by automatically generating numerous pages. Additionally, there are serious problems regarding scalability. Richardson and Domingos estimate the memory and computing time requirements for several 100,000 terms 100-200 times higher compared to the original PageRank calculations. Regarding the large number of small subsets of the web, these numbers appear to be realistic. The higher memory requirements should not be so much of a problem because Richardson and Domingos correctly state that the term specific PageRank values constitute only a fraction of the data volume of Google's inverse index. However, the computing time requirements are indeed a large problem. If we assume just five hours for a conventional PageRank calculation, then this would last about 3 weeks based on Richardson and Domingos' model, which makes it unsuitable for actual employment. Taher Haveliwala's Topic-Sensitive PageRank The approach of Taher Havilewala seems to be more practical for actual employment. Just like Richardson and Domingos, also Havilewala suggests the computation of different PageRanks for different topics. However, the Topic-Sensitive PageRank does not consist of hundreds of thousands of PageRanks for different terms, but of a few PageRanks for different topics. Topic-Sensitive PageRank is based on the link structure of the whole web, whereby the topic sensitivity implies that there is a different weighting for each topic. The basic principle of Haveliwala's approach has already been described in our section on the "Yahoo-Bonus", where we have discussed the possibility to assign a particular imporance to certain web pages. In the words of the Random Surfer Model, this is realized by increasing the probability for the Random Surfer jumping to a page after "getting bored". Via links, this manual intervention in the PageRank technique has an influence on the PageRank of each page on the web. More precisely, we have reached taking influence on PageRank by implementing another value E in the PageRank algorithm: PR(A) = E(A) (1-d) + d (PR(T1)/C(T1) + ... + PR(Tn)/C(Tn)) Haveliwala's Topic-Sensitive-PageRank goes one step further. Instead of assigning a universally higher value to a website or a web page, Haveliwala differentiates on the basis of different topics. For each of these topics, he identifies other authority pages. On the basis of this evaluation, different PageRanks are calculated - each separately, but for the entire web. For his experiments on Topic-Sensitive PageRank, Haveliwala has chosen the 16 top-level categories of the Open Directory Project both for the identification of topics and for the intervention in PageRank. More precisely, Haveliwala assigns a higher value E to the pages of those ODP categories for which he calculates PageRank. If, for example, he calculates the PageRank for the topic health, all the ODP pages in the health category receive a relatively higher value E and they pass this value in the form of PageRank on to the pages which are linked from there. Of course, this PageRank is passed on to other pages and, if we assume that health-related websites tend to link more often to other websites within that topic, pages on the topic health generally receive a higher PageRank. Haveliwala confirms the incompleteness of choosing the Open Directory Project in order to identify topics, which for example results in a high degree of dependence on ODP editors and in a rather rough subdivision into topics. But, as Haveliwala states, his method shows good results and it can surely be improved without big effort. However, one crucial point in Haveliwala's work on Topic-Sensitive-PageRank is the identification of the user's preferences. Having a Topic-Specific PageRank is useless as long as we do not know in which topics an actual user is interested. In the end, search results must be based on the PageRank that matches the user's preferences best. The Topic-Sensitive PageRank can only be used if these are known. Indeed, Haveliwala does supply some practicable approaches for the identification of user preferences. He describes, for example, the search in context by highlighting terms on a web page. In this way, the content of that web page could be an indicator for waht the user is looking for. At this point, we want to note the potential of the Google Toolbar. The Toolbar submits data regarding search terms and pages that a user has visited to Google. This data can be used to create user profiles which can then be a basis for the identification of the user's preferences. However, even without using such techniques, it is imaginable that a user simply chooses the topic he is interested in before he does a query. The Weighting of Links Based on Content Analyses That it is possible to weight single links within the PageRank technique has been shown on the previous page. The thought behind weighting links based on content analyses is to avoid the corrumption of PageRank. By weighting links this way, it is theoretically possible to diminish the influence of links between thematically unrelated page, which have been set for the sole purpose of boosting PageRank of one page. Indeed, it is questionable if it is possible to realize such weighting based on content analyses. 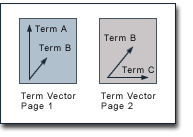 The fundamentals of content analyses are based on Gerard Salton's work in the 1960s and 1970s. In his vector space model of information retrieval, documents are modeled as vectors which are built upon terms and their weighting within the document. These term vectors allow comparisons between the content of documents by, for instance, calculating the cosine measure (the inner product) of the vectors. In its basic form, the vector space model has some weaknesses. For instance, often the assumption that if and in how far the same words appear in two documents is an indicator for their similarity is criticized. However, numerous enhancements have been developed that solve most of the problems of the vector space model. One person who excelled at publications which are based on Salton's vector space model is Krishna Bharat. This is interesting because Bharat meanwhile is a member of Google's staff and, particularly, because he is deemded to be the developer of "Google News" (news.google.com). Google News is a service that crawls news websites, evaluates articles and then provides them categorized and grouped in different subjects on the Google New website. According to Google, all these procedures are completely automated. Therefore, other criteria like, for example, the time when an article is published, are taken into account, but if there is no manual intervention, the clustering of articles is most certainly only possible, if the contents of the articles are actually compared to each other. The questions is: How can this be realized? In their publication on a term vector database, Raymie Stata, Krishna Bharat and Farzin Maghoul describe how the contents of web pages can be compared based on term vectors and, particularly, they describe how some of the problems with the vector space model can be solved. Firstly, not all terms in documents are suitable for content analsysis. Very frequent terms provide only little discrimination across vectors and, so, the most frequent third of all terms is eliminated from the database. Infrequent terms, on the other hand, do not provide a good basis for measuring similarity. Such terms are, for example, misspellings. They appear only on few pages which are likely unrelated in terms of their theme, but because they are so infrequent, the term vectors of the pages appear to be closely related. Hence, also the least frequent third of all terms is eliminated from the database. Even if only one third of all terms is included in the term vectors, this selection is still not very efficient. Stata, Bharat and Maghoul perform another filtering, so that each term vector is based on a maximum of 50 terms. But these are not the 50 most frequent terms on a page. They weight a term by deviding the number of times it appears on a page by the number of times it appears on all pages, and those 50 terms with the highest weight are included in the term vector of a page. This selection actually allows a real differentiation between the content of pages. The methods described above are standards for the vector space model. If, for example, the inner product of two term vectors is rather high, the contents of the according pages tend to be similar. This may allow content comparisons in many areas, but it is doubtful if it is a good basis for weighting links within the PageRank technique. Most of all, synonyms and terms that describe similar things can not be identified. Indeed, there are algorithms for word stemming which work good for the english language, but in other languages word stemming is much more complicated. Different languages are a general problem. Unless, for instance, brand names or loan words are used, texts in different languages normally do not contain the same terms. And if they do, these terms normally have a completely different meaning, so that comparing content in different languages is not possible. However, Stata, Bharat and Maghoul provide a method of resolution for these problems. 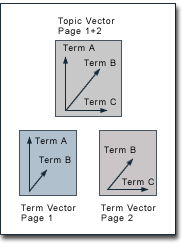 Stata, Bharat und Maghoul present a concrete application for their Term Vector Database by classifying pages thematically. Bharat has also published on this issue together with Monika Henzinger, presently Google's Research Director, and they called it "topic distillation". Topic distillation is based on calculating so-called topic vectors. Topic vectors are term vectors, but they do not only include terms of one page but rather the terms of many pages which are on the same topic. So, in order to create topic vectors, they have to know a certain amount of web pages which are on several pre-defined topics. To achieve this, they resort to web directories. For their application, Stata, Bharat und Maghoul have crawled about 30,000 links within each of the then 12 main categories of Yahoo to create topic vectors which include about 10,000 terms each. Then, in order to identify the topic of any other web page, they matched the according term vector with all the topic vectors which were created from the Yahoo crawl. The topic of a web page derived from the topic vector which matched the term vector of the web page best. That such a classification of web pages works can again be observed by the means of Google News. Google News does not only merge articles to one news topic, but also arranges them to the categories World, U.S., Business, Sci/Tech, Sports, Entertainment and Health. As long as this categorization is not based on the structure of the website where the articles come from (which is unlikely), the actual topic of an article has in fact to be computed. At the time he published on term vectors, Krishna Bharat did not work on PageRank but rather on Kleinberg's algorithm, so that he was more interested in filtering off-topic links than in weighting links. But from classifying pages to weighting links based on content comparisons, there is only a small step. Instead of matching the term vectors of two pages, it is much more efficient to match the topics of two pages. We can, for instance, create a "topic affinity vector" for each page based on the degree of affinity of the page's term vector and all the topic vectors. The better the topic affinity vectors of two pages match, the more likely are they on the same topic and the higher should a link between them be weighted. Using topic vectors has one big advantage over comparing term vectors directly: A topic vector can include terms in different languages by being based on, for instance, the links on different national Yahoo versions. Deviant site structures of the national versions can most certainly be adapted manually. Even better may be using the ODP because the structure of the sub-categories of the "World" category is based on the main OPD structure. In this way, measuring topic similarities between pages in different languages can be realized, so that a really useful weighting of links based on text analyses appears to be possible. Is there an Actual Implementation of Themes in PageRank? That both the approach of Havelivala and the approach of Richardson and Domingos are not utilized by Google is obvious. One would notice it using Google. However, a weighting of links based on text analyses would not be apparent immediately. It has been shown that it is theoretically possible. But it is doubtful that it is actually implemented. We do not want to claim that we have shown the only way of weighting links on the basis of text analyses. Indeed, there are certainly dozens of others. However, the approach that we provided here is based on publications of important members of Google's staff and, thus, we want to rest a critical evaluation on it. Like always, when talking about PageRank, there is the question if our approach is sufficienly scalable. On the one hand, it causes additional memory requirements. After all, Stata, Bharat and Maghoul describe the system architecture of a term vector database which is different from Google's inverse index, since it maps from page ids to terms and, so, can hardly be integrated in the existing architecture. At the actual size of Google's index, the additional memory requirements should be several hundred GB to a few TB. However, this should not be so much of a problem since Google's index is most certainly several times bigger. In fact, the time requirements for building the database and for computing the weigtings appear to be the critical part. Building a term verctor database should be approximately as time-consuming as building an inverse index. Of course, many procecces can probably be used for building both but if, for instance, the weighting of terms in the term vectors has to differ from the weighting of terms in the inverse index, the time requirements remain substantial. If we assume that, like in our approach, content analyses are based on computing the inner products of topic affinity vectors which have to be calculated by matching term vectors and topic vectors, this process should be approximately as time-consuming as computing PageRank. Moreover, we have to consider that the PageRank calculations themselves beome more complicated by weighting links. So, the additional time requirements are definitely not negligible. This is why we have to ask ourselves if weighting links based on text analyses is useful at all. Links between thematically unrelated page, which have been set for the sole purpose of boosting PageRank of one page, may be annoying, but most certainly they are only a small fraction of all links. Additionally, the web itself is completely inhomogeneous. Google, Yahoo or the ODP do not owe their high PageRank solely to links from other search engines or directories. A huge part of the links on the web are simply not set for the purpose of showing visitors ways to more thematically related information. Indeed, the motivation for placing links is manifold. Moreover, the problably most popular websites are completely inhomogeneous in terms of theme. Think about portals like Yahoo or news websites which contain articles that cover almost any subject of life. A strong weighting of links as it has been described here could influence those website's PageRanks significantly. If the PageRank technique shall not become totally futile, a weighting of links can only take place to a small extent. This, of course, raises the question if the efforts it requires are justifiable. After all, there are certainly other ways to eliminate spam which often comes to the top of search results through thematically unrelated and probably bought links. PageRank and Google are trademarks of Google Inc., Mountain View CA, USA. PageRank is protected by US Patent 6,285,999. The content of this document may be reproduced on the web provided that a copyright notice is included and that there is a straight HTML hyperlink to the corresponding page at pr.efactory.de in direct context. Urlaub Dominikanische Republik (c)2002/2003 eFactory GmbH & Co. KG Internet-Agentur - written by Markus Sobek |
eFactory
GmbH & Co. KG
sobek@eFactoryy.de
Goethestraße 75
40237 Düsseldorf
| Tel.: | 0211 44 03 97-21 |
| Fax: | 0211 44 03 97-40 |