

|
Themen-basierter PageRank Die themen- bzw. themengebietsbezogene Homogenität von Webseiten wird schon seit geraumer Zeit als mögliches Ranking-Kriterium von Suchmaschinen diskutiert. Für die Integration von Themen in Suchmaschinenalgorithmen gibt es die verschiedensten Denkansätze. Ihnen gemein ist, dass Webseiten nicht mehr allein aufgrund Ihrer eigenen Inhalte bewertet werden, sondern dass auch die Inhalte anderer Webseiten hierzu berücksichtigt werden. So könnten also beispielsweise die Inhalte aller Seiten einer Website Einfluss auf die Bewertung einer einzelnen Seite dieser Website nehmen. Andererseits ist es auch denkbar, dass eine Seite an den Inhalten derjenigen Seiten gemessen wird, auf die sie verlinkt oder aber von denen sie selbst verlinkt wird. Sehr kontrovers diskutiert wird der mögliche Einsatz eines themenbasierten Rankings für die Suchmaschine Google. Immer wieder finden sich in einschlägigen Foren und auf Websites zum Thema Suchmaschinenoptimierung Ratschläge, dass eingehende Links von Seiten mit thematischer Ähnlichkeit einen größeren Einfluss auf den PageRank haben als Links von anderen Seiten. Diese Annahme soll hier kritisch beleuchtet werden. Zunächst werden hierzu zwei relativ neue Ansätze zur Integration von Themen in das PageRank-Verfahren diskutiert: auf der einen Seite das Modell des "intelligenten Surfers" von Matthew Richardson und Pedro Domingos und auf der anderen Seite der Topic-Sensitive PageRank von Taher Haveliwala. Anschließend sollen Möglichkeiten aufgezeigt werden, inwieweit Inhaltsanalysen und -vergleiche dazu eingesetzt werden können, thematische Ähnlichkeiten zwischen Seiten zu berechnen, um auf dieser Basis dann eine Gewichtung von Links im Rahmen des PageRank-Verfahrens vorzunehmen. Der "intelligente Surfer" von Richardson und Domingos Matthew Richardson und Pedro Domingos ziehen zur Erläuterung ihres Ansatzes zur Implementierung von Themengebieten in das PageRank-Verfahren zunächst das Random Surfer Modell heran. Sie schlagen anstelle eines Surfers, der wahllos Links verfolgt, einen intelligenteren Surfer vor, der einerseits Links nur entsprechend seiner Suchanfrage verfolgt und andererseits auch nach dem Abbruch des Surf-Vorgangs nur Seiten aufruft, die seiner Suchanfrage entsprechen. Im Rahmen des Ansatzes von Richardson und Domingos sind für den "intelligenten Surfer" also nur Seiten relevant, die den von ihm gesuchten Begriff auch tatsächlichen enthalten. Das Random Surfer Modell ist jedoch nichts als ein Abbild des PageRank-Verfahrens. Zur Umsetzung muss also für jeden im Web existierenden Begriff eine eigene PageRank-Berechnung stattfinden. Diese Berechnung stützt sich dabei ausschließlich auf Links zwischen Seiten, die den jeweiligen Begriff enthalten. Das Modell von Richardson und Domingos wirft einige Probleme auf. Vor allem entstehen diese im Bereich von Suchbegriffen, die nicht sehr häufig im Web vorkommen. Da diese wenigen Seiten sich auch noch verlinken müssen, um in die PageRank-Berechnung eingehen zu können, basieren die Resultate auf nur sehr kleinen Subbereichen des Webs und lassen gegebenenfalls sehr relevante Seiten außen vor. Ferner ist natürlich ein kleiner Subbereich des Webs wesentlich anfälliger für Spam im Sinne der Generierung zahlreicher Webseiten. Zudem ergeben sich gravierende Probleme bezüglich der Skalierbarkeit. Richardson und Domingos schätzen sowohl den Speicher- als auch den Rechenbedarf für mehrere 100.000 Begriffe und entsprechende PageRank-Berechnungen auf das 100-200-fache des ursprünglichen PageRank-Verfahrens. Diese Zahlen klingen angesichts der großen Zahl relativ kleiner Subbereiche des Webs realistisch. Der erhöhte Speicherbedarf sollte kein grundsätzliches Problem darstellen, da Richardson und Domingos hierzu richtig anführen, dass die begriffsspezifischen PageRank-Werte nur einen Bruchteil des Datenvolumens des inversen Index Google's ausmachen dürften. Wirklich problematisch ist der Zeitbedarf für die Berechnung. Kalkulieren wir nur mit fünf Stunden für eine herkömmliche PageRank-Berechnung, so würde diese im Falle des Modells von Richardson und Domingos etwa drei Wochen in Anspruch nehmen. Dies stünde für den tatsächlichen Einsatz nicht zur Diskussion. Taher Haveliwala's Topic-Sensitive PageRank Der Ansatz von Taher Havilewala scheint für den tatsächlichen Einsatz vielversprechender. Auch Havilewala regt die Berechnung unterschiedlicher PageRanks für unterschiedliche Themenbereiche an. Hierbei sollen jedoch nicht hunderttausende PageRanks für verschiedene Subbereiche des Webs, sondern vielmehr wenige PageRanks auf der Basis des gesamten Webs berechnet werden. Bei dieser Berechnung wird zwar das gesamte Web berücksichtigt, es erfolgt jedoch jeweils eine dem Themengebiet entsprechende, unterschiedliche Gewichtung. Die Grundlagen für den Ansatz von Havilewala wurden hier schon im Abschnitt zum "Yahoo-Bonus" beschrieben. Dabei wurde die Möglichkeit aufgezeigt, spezifischen Webseiten eine besondere Bedeutung im Rahmen des PageRank-Verfahrens zukommen zu lassen. Auf das Random Surfer Modell übertragen geschah dies dadurch, dass die Wahrscheinlichkeit erhöht wird, dass der Zufalls-Surfer nach dem Abbruch eines Surf-Vorgangs eine bestimmte Seite aufsucht. Diese Einflussnahme auf das PageRank-Verfahren wirkt sich dann über Links auf den PageRank aller Seiten des Webs aus. Konkret erreicht wurde diese Einflussnahme durch die Implementierung eines weiteren Wertes E in den PageRank Algorithmus: PR(A) = E(A) (1-d) + d (PR(T1)/C(T1) + ... + PR(Tn)/C(Tn)) Havilewala geht in seinem Ansatz zum Topic-Sensitive PageRank einen Schritt weiter. Er weist keiner Site oder Seite eine grundlegende und allgemeingültige höhere Wertung zu, sondern differenziert diese auf der Basis bestimmter Themengebiete. Für jedes dieser Themengebiete identifiziert er jeweils andere Seiten mit besonderer Kompetenz. Auf der Grundlage dieser Bewertungen werden dann unterschiedliche PageRanks jeweils für das gesamte Web berechnet. In seiner Arbeit zum Topic-Sensitive PageRank wählte Haveliwala die 16 Hauptkategorien des Open Directory Projekt sowohl zur Identifizierung von Themengebieten als auch für die besondere Bewertung innerhalb der PageRank-Berechung aus. Konkret weist Haveliwala für die einzelnen PageRank-Berechnungen den jeweiligen Seiten unter den Hauptkategorien des ODP einen hohen Wert E innerhalb des PageRank Algorithmus zu. Wird etwa der PageRank für das Thema Gesundheit berechnet, erhalten die ODP-Seiten der Kategorie Gesundheit jeweils einen relativ höheren Wert E, der sich dann auf die von dort verlinkten Seiten auswirkt. Dies setzt sich natürlich fort, und unter der Annahme, dass Websites zum Thema Gesundheit sich tendenziell verstärkt gegenseitig verlinken, haben all diese Seiten im Rahmen des Themas Gesundheit einen relativ höheren PageRank. Haveliwala konstatiert die Unvollkommenheit der Wahl des Open Directory Project, die sich etwa in einer großen Abhängigkeit von den Editoren des ODP und in einer nur sehr groben Untergliederung in Themengebiete äußert, sie liefert allerdings offensichtlich bereits gute Ergebnisse und kann sicherlich ohne großen Aufwand verbessert werden. Ein Schwerpunkt der Arbeit zum Topic-Sensitive PageRank ist die Identifizierung der Präferenzen des Benutzers. Über themenspezifische Bewertungsmöglichkeiten zu verfügen ist nutzlos, so lange man nicht darüber informiert ist, welche Themengebiete für den Benutzer interessant sind. Schließlich soll für jeweilige Suchanfragen immer nur derjenige PageRank in die Seitenbewertung einfließen, der für die Suchanfrage des Benutzers auch tatsächlich relevant ist. Erst hierdurch kann der Topic-Sensitive PageRank tatsächlich genutzt werden. Auch zur Identifikation der Benutzerpräferenzen liefert Haveliwala allerdings praktikable Ansätze. So beschreibt er beispielsweise die Suche im Kontext durch Markieren eines Begriffes innerhalb eines Dokuments - und damit den Inhalt dieses Dokuments als Anhaltspunkt für die Identifizierung von Benutzerpräferenzen. An dieser Stelle soll dazu wiederum an die Möglichkeiten der Google Toolbar erinnert werden. Die Toolbar überträgt Daten zu Suchbegriffen und besuchten Seiten an Google und könnte damit leicht zur Erstellung von Benutzerprofilen dienen. Doch auch ohne Installation der Toolbar wäre letztlich eine aktive Auswahl eines Themengebiets durch den User jeweils vor seiner Suche denkbar. Die Bewertung von Links auf der Basis von Inhaltsanalysen Dass grundsätzlich eine Gewichtung einzelner Links im Rahmen des PageRank-Verfahrens möglich ist, wurde auf der vorigen Seite bereits gezeigt. Der Hintergrund einer Gewichtung von Links auf der Basis von Inhaltsanalysen würde in erster Linie in der Verhinderung der Korrumpierung des Pagerank-Verfahrens liegen. So könnte theoretisch mittels Inhaltsanalysen erreicht werden, dass Links, die ausschließlich zum Zwecke der Steigerung des PageRanks bestimmter Sites gesetzt werden, in vielen Fällen in weitaus geringerem Maße auf den PageRank Einfluss nehmen. Fraglich ist allerdings, ob eine derartige Bewertung auf der Basis von Inhaltsanalysen auch tatsächlich umgesetzt werden kann. 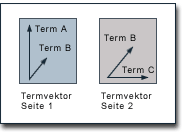 Die Grundlagen zum Vergleich von Inhalten wurden bereits in den 60er und 70er Jahren des 20. Jahrhunderts von Gerard Salton erarbeitet. Sein Vektorraummodell bildet Dokumente als Vektoren aus Termen (Begriffe innerhalb eines Dokuments) und deren Gewichtung ab. Diese Termvektoren können dann miteinander verglichen werden, indem z.B. das Kosinus-Maß (Skalarprodukt) berechnet wird, um inhaltliche Ähnlichkeiten zwischen den Dokumenten zu messen. In seiner einfachen Form weist das Vektorraummodell einige Schwächen auf. So wird etwa die grundsätzliche Annahme kritisiert, dass die Ähnlichkeit zwischen Dokumenten daran bemessen wird, ob und in welchem Ausmaß einzelne Terme tatsächlich in zwei zu vergleichenden Dokumenten vorkommen. Mittlerweile gibt es jedoch zahlreiche Erweiterungen und Verfeinerungen des Vektorraummodells die viele der Probleme beheben. Mit Arbeiten die auf Saltons Vektorraummodell aufbauen hat sich vor allem auch Krishna Bharat hervorgetan. Dies ist in erster Linie von Interesse, weil Bharat mittlerweile zu Googles Mitarbeiterstab zählt und insbesondere als Entwickler der "Google News" (news.google.com) gilt. Google News ist ein Service, der Nachrichten-Websites spidert, die einzelnen Nachrichten auswertet und anschließend in unterschiedlichen Kategorien zu unterschiedlichen Themen zusammenfasst. Nach Angaben Googles erfolgen all diese Vorgänge vollkommen automatisiert. Hierzu werden weitere Kriterien wie etwa der Zeitpunkt des Erscheinens eines jeweiligen Artikels herangezogen, sofern jedoch keinerlei manuelle Eingriffe stattfinden, ist eine Zusammenfassung unter inhaltlichen Gesichtspunkten nur möglich, wenn die Inhalte der einzelnen Nachrichten zunächst einmal tatsächlich miteinander verglichen werden. Es stellt sich nur die Frage, wir dies realisiert werden kann. In Ihrer Veröffentlichung zum Aufbau einer Termvektor-Datenbank beschreiben Raymie Stata, Krishna Bharat und Farzin Maghoul sehr anschaulich, wie Vergleiche zwischen Inhalten auf der Basis von Termvektoren realisiert und vor allem auch, wie verschiedene Hürden bei Umsetzung überwunden werden können. Zunächst besteht die Problematik, dass zahlreiche Begriffe innerhalb eines Dokuments nicht für einen Inhaltsvergleich geeignet sind. So wird aus der Gesamtheit aller Begriffe zuerst das am häufigsten vorkommende Drittel gefiltert, da diese Begriffe nur zu einem sehr geringen Grad dazu beitragen können, die Inhalte von Dokumenten voneinander zu unterscheiden. Da relativ selten vorkommende Begriffe, die z.B. auch aus Tippfehlern resultieren können, gegebenenfalls thematisch sehr unterschiedliche Dokumente sehr ähnlich erscheinen lassen, weil die entsprechenden Begriffe insgesamt sehr selten vorkommen, wird auch das am wenigsten auftretende Drittel gefiltert, womit für die Durchführung von Vergleichen nurmehr ein Drittel aller Begriffe genutzt wird. Auch wenn bereits zwei Drittel aller Begriffe nicht in die Termvektoren gelangen können, ist diese Auswahl für einen Vergleich noch wenig effizient. Stata, Bharat und Maghoul führen deshalb vor dem Aufbau der Termvektoren eine weitere Filterung durch, so dass ein Termvektor jeweils auf maximal 50 Begriffen basiert. Diese 50 Begriffe sind jedoch nicht etwa die 50 am häufigsten innerhalb eines Dokuments auftretenden Begriffe. Vielmehr werden die 50 Begriffe genutzt, für die die Relation aus dem Vorkommen innerhalb eines Dokuments zum Vorkommen innerhalb der Gesamtheit aller Dokumente am größten ist. Gerade hierdurch wird es möglich, die Inhalte von Dokumenten tatsächlich voneinander abzugrenzen. Die beschriebenen Maßnahmen sind Standards im Rahmen der Nutzung von Termvektoren. Wenn z.B. das Skalarprodukt aus zwei derart ermittelten Termvektoren relativ hoch ist, sind die beiden entsprechenden Seiten einander unter thematischen Gesichtspunkten tendenziell ähnlich. Diese Vorgehensweisen ermöglichen Inhaltsvergleiche in vielen Bereichen, ob sie allein jedoch für unser Ziel der Gewichtung von Links im Rahmen des PageRank-Verfahrens ausreichend sind, ist zu bezweifeln. Schließlich können vor allem Synonyme, aber auch andere Begriffe, die Ähnliches umschreiben, mittels der beschriebenen Vorgehensweisen nicht identifiziert werden. Für das Problem der Zusammenfassung von Singular und Plural etwa, existieren für die englische Sprache relativ einfache Algorithmen. In anderen Sprachen ist dies jedoch ungleich schwerer zu bewältigen. Unterschiedliche Sprachen sind dabei ein grundsätzliches Problem. Bis auf die Ausnahme von z.B. Lehnwörtern oder Markennamen werden verschiedensprachige Texte in der Regel keine gemeinsamen Begriffe enthalten, oder aber gemeinsame Begriffe haben eine völlig unterschiedliche Bedeutung, so dass ein Vergleich zwischen Texten in unterschiedlichen Sprachen nicht möglich ist. Doch auch hierfür bieten Stata, Bharat und Maghoul einen Lösungsansatz. 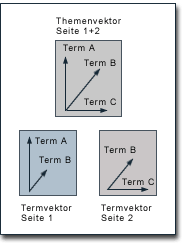 Stata, Bharat und Maghoul zeigen eine sehr konkrete Anwendungsmöglichkeit ihrer Termvektor-Datenbank auf, indem Sie für einzelne Dokumente ein entsprechendes, vordefiniertes Themengebiet identifizieren. Über diese Identifizierung von Themengebieten hat Bharat auch gemeinsam mit Monika Henzinger - derzeit Research Director bei Google - veröffentlicht, und sie funktioniert folgendermaßen: Zunächst werden sogenannte Themenvektoren berechnet. Themenvektoren sind selbst auch Termvektoren, nur dass Sie nicht auf den Inhalten einer einzelnen Webseite basieren, sondern auf den Inhalten vieler Webseiten, denen eine inhaltliche Ähnlichkeit gemein ist. Um einen Themenvektor aufbauen zu können, muss es für jedes vordefinierte Themengebiet eine bestimmte Anzahl an Webseiten geben, für die bekannt ist, welchem Themengebiet sie zugeordnet werden können. Zu diesem Zwecke greifen Stata, Bharat und Maghoul auf Web-Verzeichnisse zurück. In einer konkreten Anwendung von Themenvektoren haben sie auf der Basis von jeweils ca. 30.000 Links innerhalb der damals 12 Hauptkategorien des Yahoo-Verzeichnisses Themenvektoren mit einem Umfang von jeweils ca. 10.000 Begriffen gebildet. Um das Thema einer Webseite identifizieren zu können, haben sie anschließend die Ähnlichkeiten zwischen dem entsprechenden Termvektor und den einzelnen Themenvektoren berechnet. Derjenige Themenvektor, für den der höchste Wert ermittelt wird, bestimmt das Thema der Webseite. Dass die Einordnung von Themen in der Praxis gut funktioniert kann wiederum anhand von Google News beobachtet werden. Einzelne Artikel werden nicht nur zu einem konkreten Thama zusammengefasst, sondern auch noch in eine der Kategorien World, U.S., Business, Sci/Tech, Sports, Entertainment und Health eingeordnet. Solange eine derartige Kategorisierung nicht über die Website-Strukturen der Quellen für die Artikel erfolgt (was unwahrscheinlich ist), muss tatsächlich das Thema eines Artikels bzw. einer Gruppe von Artikeln berechnet werden. Krishna Bharat beschäftigte sich zum Zeitpunkt seiner Veröffentlichungen nicht mit PageRank, sondern vielmehr mit dem Kleinberg-Algorithmus, so dass er weniger die Gewichtung von Links als vielmehr das Filtern von inhaltlich unzusammenhängenden Links verfolgt hat. Der Schritt zu einem Vergleich von Inhalten für die Gewichtung von Links im Rahmen des PageRank ist jedoch nur kurz. Anstatt der Inhalte von zwei sich verlinkenden Seiten werden nurmehr die für sie identifizierten Themengebiete verglichen. So könnten beispielsweise die Grade der Zugehörigkeit eines jeden Dokuments zu jeweils allen Themengebieten in einem Themenzugehörigkeitsvektor erfasst werden. Diese Vektoren können dann als Grundlage für den Vergleich zweier sich verlinkender Webseiten gewählt werden und somit der Gewichtung der Links dienen. Die Nutzung von Themenvektoren bietet gegenüber dem direkten Vergleich von Termvektoren einen wesentlichen Vorteil: Ein Themenvektor kann auf Begriffen aus unterschiedlichen Sprachen basieren. Hierzu müssen lediglich z.B. Seiten aus den nationalen Yahoo-Versionen berücksichtigt werden. Mögliche Abweichungen in den Verzeichnis-Strukturen können sicherlich manuell angepasst werden. Besser wäre gegebenenfalls ein Rückgriff auf das ODP, dessen Strukturen sich innerhalb der Kategorie "World" an die Struktur der Hauptkategorien anlehnen. Hierdurch wäre die Feststellung thematischer Ähnlichkeiten zwischen verlinkenden Seiten auch multilingual zu realisieren, so dass eine sinnvoll geartete Gewichtung von Links auf der Basis von Inhaltsanalysen durchaus möglich erscheint. Gibt es eine tatsächliche Implementierung von Themen in das PageRank-Verfahren? Dass die Ansätze von Haveliwala sowie Richardson und Domingos zwar durchaus interessant sind, aber derzeit nicht eingesetzt werden, ist offensichtlich. Man könnte es unmittelbar bei der Nutzung Googles erkennen. Eine Gewichtung von Links auf der Basis von Inhaltsanalysen hingegen wäre nicht unmittelbar zu bemerken. Dass sie theoretisch möglich ist, wurde gezeigt. Ob sie aber auch praktisch umgesetzt wird, ist durchaus zweifelhaft. Es soll an dieser Stelle nicht der Anspruch erhoben werden, den einzig möglichen Weg zur Gewichtung von Links aus der Basis von Inhaltsanalysen aufgezeigt zu haben. Es gibt in der Tat sicherlich dutzende andere. Der hier vorgestellte orientiert sich jedoch an Veröffentlichungen wichtiger Google-Mitarbeiter, was ihn dazu qualifiziert, auf ihn eine kritische Beurteilung zu stützen. Wie immer im Rahmen des PageRank-Verfahrens, so stellt sich auch hier die Frage, ob ein Einsatz der vorgestellten Lösung hinreichend skalierbar ist. Einerseits erfordert sie zusätzliche Speicherkapazitäten. Die zitierte Arbeit von Stata, Bharat und Maghoul beschreibt schließlich gerade die Architektur einer Termvektoren-Datenbank, die sich in Ihrer Struktur grundlegend von Google's inversem Index unterscheidet, da sie aus Effizienzgründen von Seiten-IDs auf Terme referenziert und damit kaum in bestehende Architekturen integriert werden kann. Der zusätzliche Speicherbedarf dürfte für die aktuelle Indexgröße zwischen mehreren hundert GB und wenigen TB liegen. Dies sollte angesichts eines um ein Vielfaches größeren Index allerdings nicht sehr ins Gewicht fallen. Problematischer ist der Zeitbedarf für den Aufbau der Datenbank und die Berechnung der Gewichtungen. Der Aufbau einer Termvektor-Datenbank sollte sich unter zeitlichen Aspekten etwa in der Größenordnung des Aufbaus des inversen Index bewegen. Natürlich können wir davon ausgehen, dass etliche Prozesse gleichsam für den Aufbau beider Datenbanken genutzt werden können. Sobald jedoch zum Beispiel die Gewichtung der Terme innerhalb einzelner Termvektoren von ihrer Gewichtung innerhalb des Index abweichen muss, bleibt der Zeitbedarf erheblich. Sofern wir davon ausgehen, dass wie in unserem Lösungsansatz hier, das Skalarprodukt der aus Term- und Themenvektoren errechneten Themenzugehörigkeitsvektoren bestimmt werden soll, so können wir davon ausgehen, dass dieser Prozess einen Zeitaufwand darstellt, der sich im Rahmen der eigentlichen PageRank-Berechnung bewegt. Natürlich muss auch hier bedacht werden, dass die PageRank-Berechnung selbst durch die Gewichtung von Links zusätzlich an Komplexität gewinnt. Der zusätzliche Aufwand wäre also gewiss nicht unerheblich. Vor allem auch deshalb stellt sich die Frage, ob eine Gewichtung von Links überhaupt sinnvoll ist. Links, die zwischen thematisch unzusammenhängigen Seiten allein zum Zwecke der PageRank-Erhöhung einer der beiden Seiten gesetzt werden, mögen zwar ärgerlich sein, sie dürften jedoch nur einen minimalen Anteil an der Gesamtheit aller Links ausmachen. Andererseits ist das Web an sich vollkommen inhomogen. Google, Yahoo oder das ODP verdanken ihren hohen PageRank sicherlich nicht nur eingehenden Links von anderen Suchdiensten. Ein großer Teil der Links innerhalb des Webs werden einfach nicht mit dem Ziel gesetzt, Besuchern einen Weg zu weiteren, thematisch verwandten Informationen zu weisen. Die Motivation für das Setzen von Links ist vielmehr vielfältig. Weiterhin sind die wohl beliebtesten Websites in sich vollkommen inhomogen. Man denke nur an Portale wie Yahoo oder aber an Nachrichten-Websites, deren Artikel allen Bereichen menschlichen Lebens entstammen. Eine starke Gewichtung von Links in der hier beschriebenen Form würde sich drastisch auf ihren PageRank auswirken. Eine Gewichtung von Links dürfte also nur sehr eingeschränkt stattfinden, wenn das PageRank-Verfahren nicht ad absurdum geführt werden soll. Dies wirft dann natürlich die Frage auf, ob dann der erforderliche Aufwand gerechtfertigt ist. Schließlich gibt es durchaus andere Möglichkeiten, den Spam, der beispielsweise durch erkaufte, thematisch unzusammenhängende Links in den Suchergebnissen nach vorn kommen kann, an das das Ende der Suchergebnisse zu verbannen. PageRank und Google sind geschützte Marken der Google Inc., Mountain View CA, USA. Das PageRank Verfahren unterliegt dem US Patent 6,285,999. Sämtliche Inhalte dieser Website können im WWW wiedergegeben werden, sofern im unmittelbaren Zusammenhang Angaben zum Copyright erfolgen und ein direkter HTML-Link auf die entsprechende Seite unter pr.efactory.de gesetzt wird. DX4400 IT Strategie IT Kostensenkung (c)2002/2003 eFactory GmbH & Co. KG Internet-Agentur - verfasst von Markus Sobek |
eFactory
GmbH & Co. KG
sobek@eFactoryy.de
Goethestraße 75
40237 Düsseldorf
| Tel.: | 0211 44 03 97-21 |
| Fax: | 0211 44 03 97-40 |